Authority notebook
Created 4 Sep 2012 • Last modified 30 Mar 2013
Initial thinking
I want to explore my idea of vicarious restraint. It seems to fit well with the idea of moral self-licensing (Merritt, Effron, and Monin (2010)). In Merritt et al.'s terms, I'm imagining that forbidding children from indulging in certain things provides the moral credentials (as opposed to moral credits) for adults to indulge in them. "It's not that media violence is bad; it's just not suitable for children." "BDSM is fine so long as it's practiced by consenting, mature adults." And so on.
How is my thinking tricky, that is, not an immediate implication of Merrit et al.? Well, forbidding children from doing something isn't a clearly moral act the way giving money to a hobo is. And watching violent movies isn't clearly immoral the way cheating is. These aren't huge leaps considering that Monin's website talks about how he's less interested in trolley problems than "everyday morality", "mundane behaviors that actors may imbue with moral content (e.g., prejudice, hypocrisy, unsafe sex, personal hygiene), even if they are not prototypical examples of traditional morality". A bigger leap is that I imagine the real-life credentialing process is large-scale and highly indirect. Individual adults need not themselves prevent children from seeing violent movies or even write a letter to a newspaper seeing that children shouldn't see violent movies in order to benefit from society's protectionism. They can take advantage of it implicitly. In our culture, the pleasures of R-rated movies are so tightly bound up with the idea of adulthood that teenagers may well be attracted to them in order to feel more grown-up. In short, I'm imagining a quiet background war of concepts, similar to how, in terror-management theory, people spend much of their lives managing terror, in one way or another, even though they rarely think about death. One concrete prediction of this subtler kind of moral credentialing is that merely reminding subjects of the smut–adulthood link should have a licensing effect.
Possible manipulations
- Have subjects read or write essays about:
- How smut is inappropriate for children.
- How smut is inappropriate, period.
- Some other moral topic, in a similarly condemnatory tone. (An obvious issue for the self-licensing concept which I don't think has been addressed is how domain-specific it is: does being Definitely Not Racist at time A license one to be more sexist at time B?)
- Have subjects read a story in which a child is denied access to smut.
- Have subjects read a story in which a child accesses smut but the consequences for the child are manipulated.
- Give subjects some kind of smut-reviewing task. You might explicitly ask what ages the material is appropriate for, or you could ask less specifically what sorts of audiences the material is appropriate for. (Such an experiment run in former decades would've resulted in a lot of people saying certain materials are inappropriate for women (or even servants), but smut protectionism nowadays seems exclusively age-based, at least in the West.)
- Ask subjects about what movies they would be willing to bring their own (assumedly hypothetical) children to, or what movies they would be willing to show in a classroom.
- Ask subjects to recommend some movies to a child.
Possible DVs
- What media the subject selects for themself, for their private enjoyment (perhaps as compensation for participating in the experiment) or ostensibly as part of an unrelated experiment.
- The subject's attitudes about how permissible, safe, or moral consuming or producing smut is for the subject, for adults, or in general.
- Moral attitudes or behavior in a different domain.
A possible future extension
Does condemning some sexual behaviors (like homosexuality) license other sexual behaviors?
Differences between kinds of smut
The five kinds of smut:
- Sex
- Violence
- Drugs
- Profanity
- Gambling
Gambling is often seen as a matter of stupidity rather than morality (right?).
Drugs are tricky at least insofar as attitudes vary widely by drug. Cannabis is very tricky; there's too much disagreement between individuals and between cultures. Tobacco is increasingly seen as just plain stupid (right?). Alcohol of all drugs probably is the best example of an age divide. Drinking is celebrated in adults and condemned in adolescents.
People mostly agree that children need to be protected from media violence, but I think it's less common for adults to like violent media than to like drinking, if only because of the gender gap. People also mostly agree that children need to be protected from sex, but again, there's a gender gap for interest in pornography or weird sex acts or other particularly smutty varieties of sexual behavior.
Something simple to start with
Handy reference: A sample schedule of fines
IV: Some simple task in which subjects get to protect children
- One idea: The subject is asked whether they'd support an ordinance regarding underage drinking, which seems clearly justified.
- Another: The subject is asked what sentence they would give to a kid who committed some alcohol-related crime.
Let's use an empty control condition for now just to check that the manipulation does something. If the manipulation works (or if it goes in the wrong direction!), then we can try more sophisticated control conditions to dissect the effect.
Suppose a legislature is considering a bill that would greatly increase penalties to businesses who sell alcoholic beverages without checking the age of the buyer. A committee, after reviewing published research and performing original statistical analyses of communities that passed comparable laws, concludes that the bill would reduce drunk driving-related injuries among teenagers by 24%.
Would you support the bill?
- [Yes]
- [No]
DV: The subject is asked whether they would drink in some situation where they're not technically allowed to or it's somehow socially unacceptable.
- Perhaps better: The subject is asked what sentence they would give to an adult who committed some alcohol-related crime.
Suppose a 31-year-old man is arrested for driving with an open can of beer, violating a local open-container law. However, his blood alcohol content is .02%, which is below the legal limit. He has no criminal record.
How much should the man be fined? Answer according to what you personally feel is appropriate, not what you think is standard.
- No fine (let him off with a warning)
- $20
- $50
- $70
- $100
- $200
- $500
- $1,000
TV 1
ss(sb, tv == 1)[qw(age, gender, punish.nc, oc.fine, drink.age)]
| age | gender | punish.nc | oc.fine | drink.age | |
|---|---|---|---|---|---|
| s0001 | 25 | Male | Relent | $20 | 18 |
| s0002 | 58 | Male | NoOpp | $50 | 21 |
| s0003 | 61 | Female | NoOpp | $100 | 18 |
| s0004 | 37 | Male | Relent | $50 | 21 |
| s0005 | 31 | Male | NoOpp | $500 | 18 |
| s0006 | 33 | Male | NoOpp | $1k | 18<x<21 |
| s0007 | 24 | Male | NoOpp | $200 | 18 |
| s0008 | 27 | Male | Punish | 0 | 18 |
| s0009 | 20 | Male | NoOpp | $20 | 18 |
| s0010 | 23 | Male | NoOpp | $100 | 18 |
| s0011 | 30 | Male | Punish | 0 | 18 |
Hmm, it's not bad how the two subjects who accepted the ordinance ("Punish") also declined to fine the adult. But I really want to keep the probability of declining to protect children low, since I don't know how to interpret "no" answers ("Relent"), and if I exclude people who say "no", then I have a mortality issue. So I want to change the manipulation.
The fact that most of the subjects preferred 18 to 21 as a drinking age suggests that there's already some popular resentment about child protectionism with respect to booze. So why don't I change the drug used for the manipulation to tobacco? The age for buying tobacco is always 18, so there isn't the 18-versus-21 issue, and people are likelier to have negative attitudes towards tobacco in general than booze in general. The trick is that I'll be relying on a cross-domain sort of moral-credentialing process, which hasn't itself been previously demonstrated, to my knowledge. Oh well; I feel like the whole idea of vicarious restraint already relies on moral credentials being flexibly applicable, so it's not too much of an extra jump.
TV 2
Great, the change from booze to tobacco seems to have worked. Agreement with the ordinance is acceptably high:
table(ss(sb, tv == 2)$punish.nc)
| count | |
|---|---|
| NoOpp | 30 |
| Punish | 32 |
| Relent | 4 |
Unfortunately, the effect of the manipulation seems to be in the wrong direction. Also, it looks like we have a bit of a floor effect: perhaps not everybody agrees with open-container laws.
dodge(punish.nc, oc.fine, data = ss(sb, tv == 2), discrete = T) +
boxp
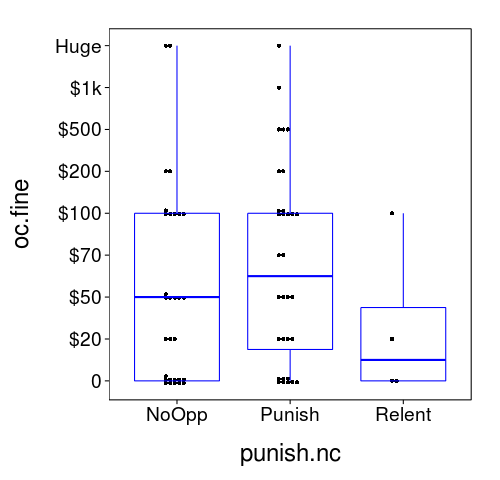
Let's do some statistical inference to see how sure I can be of the manipulation's effect. I'll use a Bayesian ordinal probit regression model in which the dependent variable is oc.fine.
Manipulation only
j1 = go.real(model.ordinal.manip_only,
ss(sb, tv == 2 & punish.nc != "Relent"))
gelman.diag(j1$samp)
| Upper C.I. | |
|---|---|
b.protect_kids |
1.00 |
t_diffs[1] |
1.04 |
t_diffs[2] |
1.01 |
t_diffs[3] |
1.02 |
t_diffs[4] |
1.01 |
t_diffs[5] |
1.01 |
t_diffs[6] |
1.01 |
t_diffs[7] |
1.02 |
threshold1 |
1.01 |
In the below plot, the colored bars show the distribution of responses predicted by the model, and the black bars show the difference between the predicted response and the actual response.
distribution.plot(j1)
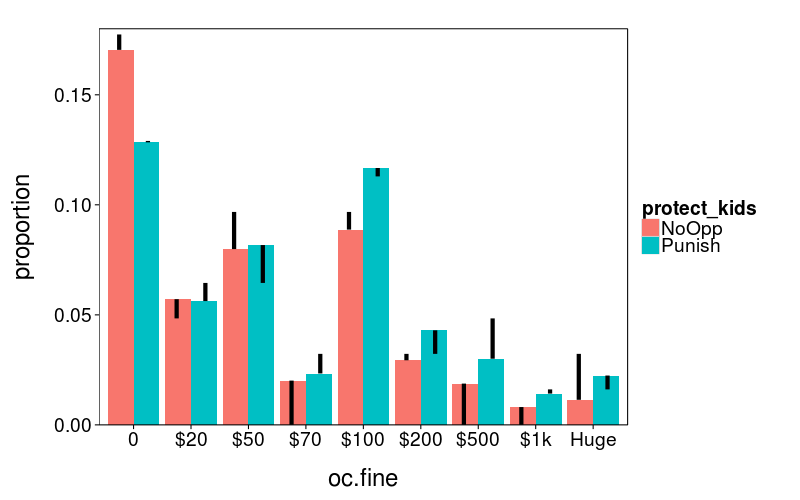
I judge this not too bad a fit, especially for the two bumps at $0 and $100. It's nice how the ordinal model has effectively captured the anchoring effect whereby there's a bump at $100 assumedly because 100 is a round number.
mean(j1$jsamp$b.protect_kids > 0)
| value | |
|---|---|
| 0.866 |
So under this model, the probability is 87% that the manipulation increased fines.
With other predictors
Let's add a dichotomous predictor for gender, an interaction term for gender and the manipulation, and a linear predictor for (age - 18).
j2 = go.real(model.ordinal.mgai,
ss(sb, tv == 2 & punish.nc != "Relent"),
n.adapt = 1500)
gelman.diag(j2$samp)
| Upper C.I. | |
|---|---|
b.age |
1.04 |
b.female |
1.07 |
b.protect_kids |
1.07 |
b.protfem |
1.09 |
t_diffs[1] |
1.00 |
t_diffs[2] |
1.01 |
t_diffs[3] |
1.01 |
t_diffs[4] |
1.00 |
t_diffs[5] |
1.01 |
t_diffs[6] |
1.00 |
t_diffs[7] |
1.01 |
threshold1 |
1.04 |
distribution.plot(j2)
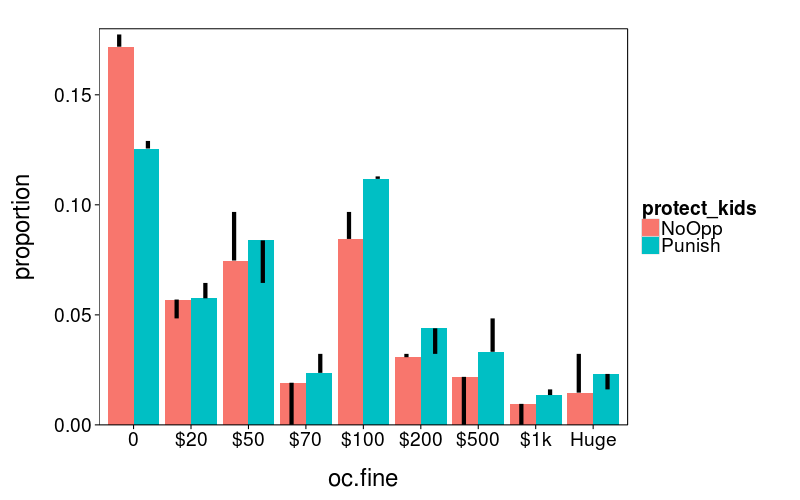
Surprisingly, this fancier model hasn't been able to match the overall proportion any better.
sapply(qw(b.protect_kids, b.female, b.protfem, b.age),
function (v) mean(j2$jsamp[[v]] > 0))
| value | |
|---|---|
| b.protect_kids | 0.839 |
| b.female | 0.973 |
| b.protfem | 0.183 |
| b.age | 0.843 |
The probability that b.protect_kids is positive is similar to that in the other model. Now let's try comparing the sizes of this model's different effects.
round(digits = 2, rbind(
t(sapply(qw(b.protect_kids, b.female, b.protfem),
function (v) qmean(j2$jsamp[[v]]))),
"20 * b.age" = qmean(20 * j2$jsamp$b.age)))
| lo | mean | hi | |
|---|---|---|---|
| b.protect_kids | -0.45 | 0.37 | 1.10 |
| b.female | -0.01 | 0.88 | 1.81 |
| b.protfem | -1.69 | -0.56 | 0.66 |
| 20 * b.age | -0.25 | 0.30 | 0.84 |
The gender effect seems stronger than the manipulation:
mean(abs(j2$jsamp$b.female) > abs(j2$jsamp$b.protect_kids))
| value | |
|---|---|
| 0.841 |
The age effect, on the scale of 20 years, seems roughly comparable.
There's other model-checking work I could do (e.g., checking the distribution of responses for women in particular), but this model basically agrees with the former with respect to the effect of the manipulation, which was the real interest, so there doesn't seem much of a point to trying harder to distinguish them.
Conclusions
In this study, the manipulation probably had the opposite of the intended effect. That is, subjects given the opportunity to protect teenagers by punishing businesses who sell tobacco to the underage were subsequently inclined to give a bigger fine to an adult who violated an open-container law. A plausible explanation is that subjects given the manipulation got into a more punitive mindset. In particular, they were reminded of how punishing people for breaking niggling laws can in fact be useful. One could even construe the effect as escalation of commitment.
New thinking
The third-person effect
The third-person effect per se is the phenomenon whereby people expect to be less affected by smut (and be less susceptible to other deleterious media effects) than other people are. A natural prediction is that the greater this gap, the more people will support censorship; the meta-analysis of Feng and Guo (2012) concluded that this prediction is indeed borne out, although the effect is weak. My idea of vicarious restraint is also an explanation for support for censorship. It differs from the third-person effect in that (a) the distinction is between "us" and "them" (adults vs. children) instead of "me" and "everybody else" and (b) there's the added idea that exercising censorship provides moral credentials for oneself or one's own group. In my own theorizing, I haven't emphasized media consumption in particular as much as the literature on the third-person effect has. But that's not too important because there's already literature on how people have a variety of self-serving perceptions compared to other people; it's just that this isn't usually called "the third-person effect".
Given these considerations, perhaps I can make my life easier by focusing on just one of these extensions of the third-person effect:
- An "us"–"them" difference as opposed to a "me"–"everybody else" difference: do people have greater perceptions of susceptibility for outgroups than ingroups, or is the distinction of importance really just oneself versus others?
- Censorship providing moral credentials. More trickily, mere reminders of censorship or other kinds of safeguards against harm that don't apply to oneself providing moral credentials. (Perhaps, for example, disallowing felons from buying guns makes nonfelonious people more comfortable buying guns.) Arguably, this prediction better captures the interesting part of vicarious restraint.
The first, I think, is implied by existing literature. The third-person perception gap seems to be enhanced for other people who are of further social distance; for example (quoting from Elder, Douglas, and Sutton (2006)), Cohen, Mutz, Price, and Gunther (1988) "found a linear increase in the TPE [third-person effect] as the comparison other changed from 'other Stanford students' to 'other Californians' and finally the 'public at large'". And Elder et al. (2006) found that for a pro-outgroup message, outgroups were perceived as more influenced than ingroups (and ingroups were perceived as more influenced than oneself).
The second can be further broken down:
- If I protect some people from deleterious media effects, I get some moral credentials.
- I can apply moral credentials towards consuming potentially harmful media (guilty pleasures?).
- I can get moral credentials from other people's actions as opposed to my own. (Kouchaki (2011) showed that this is apparently true when it comes to racism, provided that the other people belong to the ingroup.)
And a lurking background proposition that's relevant (but hopefully not crucial) to the connection between 1 and 2, and which I mentioned earlier:
- Moral credentials can cross domains. For example, being Definitely Not Racist at time 1 can credential one to be more sexist at time 2. Some support for this is provided by Mazar and Zhong (2010), who found that people given the opportunity to buy "green" products (vs. conventional products) were less generous in a subsequent dictator game and were more likely to lie and steal to get more money. Some less direct support is provided by Sachdeva, Iliev, and Medin (2009) and Jordan, Mullen, and Murnighan (2011), who found that subjects who described or recalled themselves positively or morally (compared to subjects who described themselves negatively) acted less prosocially.
And the extension to 3 that's most interesting to me is:
- I can get moral credentials from a general arrangement of society (e.g., gun control) rather than an individual's actions (e.g., behaving responsibly with a gun).
Notice that in 5, compared to, say, 1, it is more difficult to describe the effect in terms of moral credits as opposed to moral credentials. If I didn't help enact gun control myself, and I don't particularly identify with whoever did, I don't get to feel I've done anything good. Rather, the existence of gun control suggests my use of guns is less dangerous than it might seem.
Now what?
Well, I'd really like to run a study from which something interesting could be learned regardless of the outcome. This business of social-psychology experiments that are only interpretable if they turn out as expected is dangerous—it's one reason I've run a lot of subjects without having many manuscripts to show for it. Too often, the design of my studies hasn't allowed me to conclude anything when I've found the manipulation has had little or no effect or an effect in the wrong direction. It seems wiser to choose topics and designs such that a lack of an effect is somehow enlightening.
So let's put 5 aside for now. To me, it's the most interesting of the five hypotheses, but it's hard to falsify (I can't manipulate society; I can only remind people of society's arrangements), and if I did successfully falsify it, only I would care.
I'm leaning towards investigating 1. One trick is that it isn't clear whether a dependent measure regarding media consumption or more straightforwardly antisocial behavior is more likely to work. A media-consumption DV would depend on 2, whereas an unrelated DV would depend on 4.
Some vague ideas:
- The subject imagines they're head of some private transportation company and they get the opportunity to ban cigarette advertising. You could make this feel more altruistic by saying this will result in decrease in revenue. (Or don't, since this would be kind of a confound otherwise.)
- Pornographic moral credits: Do subjects who get to do something feministic (like the manipulation in Study 1 of Monin and Miller (2001)) thereafter admit to more pornography usage?
Now, the moral-credential effect in the context of vicarious restraint for media is that people should feel less susceptible to bad media effects (like racist media making you more racist) after exercising censorship concerning such media.
Perhaps a good general question: How does exercising censorship affect people's attitudes about vulnerability to the material being censored—vulnerability of other people and of oneself?
Even more generally: How does protecting people from some potential threat affect people's attitudes about vulnerability to said threats?
Basic idea for a new study
Let's pursue that first general question ("How does exercising censorship affect people's attitudes about vulnerability to the material being censored—vulnerability of other people and of oneself?"). If I get an effect, then I can worry about what follow-up studies to run in order to explain it. Let's not put too many eggs in one theoretical basket at this early stage.
The obvious design here is a study in which subjects do or do not get an opportunity to censor some dangerous media, and then I measure their beliefs about susceptibility to said media, for themselves and for a range of other agents or social groups. As before, I want subjects to be highly likely to take that opportunity if it's offered, so let's take something folks will be eager to censor. I'm inclined to use racist media, but I'm afraid I'll get a floor effect for perceptions of influence on oneself. Everybody will think themselves immune to racist propaganda. Hmm, so then perhaps it shouldn't be propaganda. Consider (a film about?) some kind of scientific study. I could say that various experts have denounced it as inaccurate—providing justification for censorship even among subjects who are inclined not to censor research reports—but also say that these inaccuracies are beyond lay ability to detect and ask the subject to make those vulnerability judgments for people who haven't heard of the experts' objections. Subjects will then be kind of obliged to not jump to the conclusion that they won't be influenced. Still, I'll need to make the scale wide, since I can expect the variability of interest for judgments about oneself to be clustered on the lower end.
One way I could help avoid a floor effect is use something like discrimination against blondes or left-handed people. I could still keep censorship agreement high using the objecting-experts business.
Another possible help: use susceptibility scales asking "How likely do you think it is that such-and-such would be influenced, even if only a little?" instead of "How much do you think such-and-such would be influenced?"
Now, along the lines of what I was saying before, what could I learn from finding no effect in this study? Well, I think the idea that the third-person effect causes censorship would be strengthened, because I would have evidence that the reverse causal relationship doesn't exist.
Okay, here's my idea; and by using deception, I can avoid a purely hypothetical manipulation, too. Subjects are told I'm gonna do this study on a whole bunch of kids that will involved having them consume some media supposedly showing that left-handed people are stupid and evil. I'll say that I'll debrief these kids but I'm conflicted about the whole procedure because I know that it's hard to disbelieve stuff (especially for kids? woo ageism!). The manipulation is that some subjects will also be asked if I should get around this problem by having the kids read analogous vignettes about aliens or something. The DVs will ask subjects how likely each party would be to be influenced by the original version.
On second thought, the subjects of the imaginary experiment should either be teenagers or unspecified people. Otherwise, I'm afraid subjects will infer that the imaginary stimulus is simplistic enough that adults (like the subject) would laugh it off.
Also, let's use albinism instead of left-handedness. The chance is of course much lower that subjects will be albino or know an albino personally than that they'll have analogous experience with left-handedness. And prejudice towards albinos has more face credibility than prejudice towards lefties, since albinos can look so strange.
TVs 3 to 5
(The only change from TV 3 to TV 4 was a tweak to response-bar positioning to reduce response set. The changes for TV 5 were an adjustment to the random-assignment procedure and an increase of HIT reward to $0.20.)
vuln.plot = function(varname)
dodge(censor, get(varname), data = ss(sb, tv %in% 3:5 & good)) +
boxp +
scale_y_continuous(
limits = c(0, 1), breaks = seq(0, 1, .2),
name = varname, expand = c(0, 0))
censor.means.boot = function(v)
with(ss(sb, tv %in% 3:5 & good & censor != "Refuse"),
boot.compare(get(v), factor(censor), stat = mean))
vuln.plot("vuln.s")
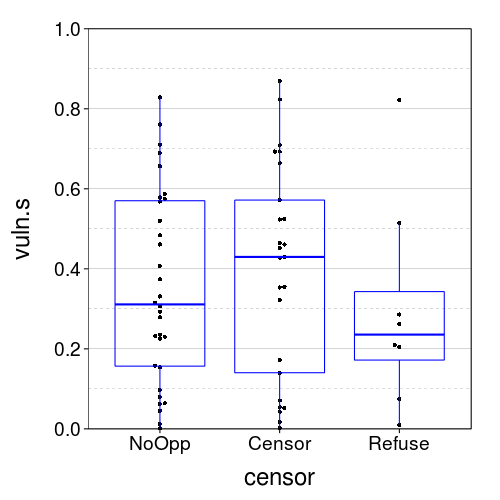
All medians are below .5, which is good. The bimodality of Censor is annoying.
censor.means.boot("vuln.s")
| lo | hi | conf | |
|---|---|---|---|
| NoOpp | 0.27 | 0.44 | |
| Censor | 0.29 | 0.50 | |
| Censor > NoOpp | 0.74 |
That's in the wrong direction: subjects felt more vulnerable when they had an opportunity to censor the film.
vuln.plot("vuln.adult")
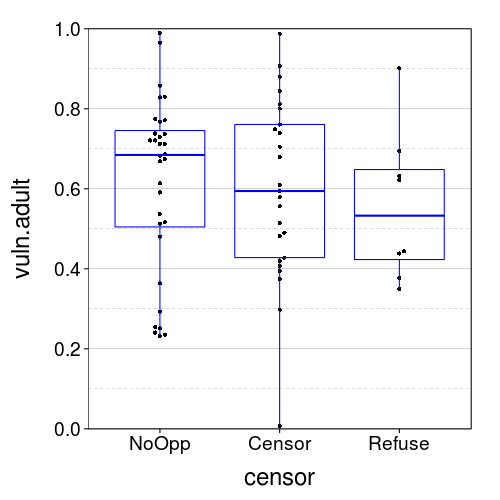
censor.means.boot("vuln.adult")
| lo | hi | conf | |
|---|---|---|---|
| NoOpp | 0.54 | 0.69 | |
| Censor | 0.51 | 0.69 | |
| NoOpp > Censor | 0.59 |
Let's check that I replicated the third-person effect:
round(digits = 2, with(ss(sb, tv %in% 3:5 & good),
mean(vuln.adult > vuln.s)))
| value | |
|---|---|
| 0.91 |
Most subjects gave a higher vulnerability rating to a typical adult than to themselves.
dby(ss(sb, tv %in% 3:5 & good), .(censor),
tpe = round(mean(vuln.adult > vuln.s), 2))
| censor | tpe | |
|---|---|---|
| 1 | NoOpp | 0.91 |
| 2 | Censor | 0.88 |
| 3 | Refuse | 1.00 |
However, this third-person effect doesn't seem to differ much by condition. I guess that's good.
vuln.plot("vuln.10yo")
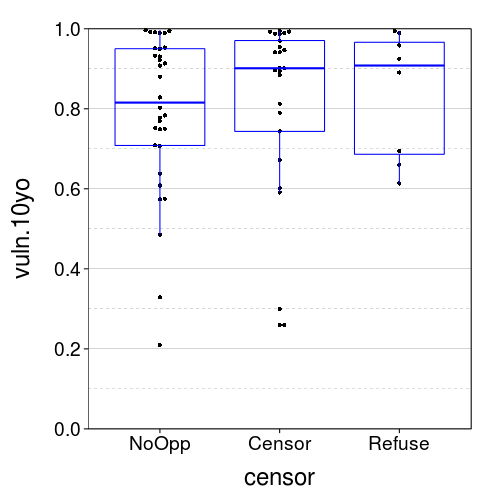
We have a ceiling effect here, which makes sense.
censor.means.boot("vuln.10yo")
| lo | hi | conf | |
|---|---|---|---|
| NoOpp | 0.72 | 0.86 | |
| Censor | 0.71 | 0.89 | |
| Censor > NoOpp | 0.62 |
Below is an attempt at Bayesian modeling that I eventually abandoned.
Modeling
dbeta.munu = defmacroq(mu, nu, expr =
dbeta(mu * nu, (1 - mu) * nu))
rbeta.munu = function(n, mu, nu)
rbeta(n, mu * nu, (1 - mu) * nu)
tv3.model1 = list(
bugs = as.bugs.model(
{# Priors
vuln.s.b0 ~ dnorm(0, 100^-2)
vuln.adult.b0 ~ dnorm(0, 100^-2)
vuln.10yo.b0 ~ dnorm(0, 100^-2)
b.censor.s ~ dnorm(0, 100^-2)
b.censor.adult ~ dnorm(0, 100^-2)
b.censor.10yo ~ dnorm(0, 100^-2)
b.subject.sigma ~ dunif(.1, 100)
for (s in 1 : N.subjects)
{b.subject[s] ~ dnorm(0, b.subject.sigma^-2)}
nu ~ dunif(2, 1000)
# Likelihood
for (s in 1 : N.subjects)
{vuln.s.mu[s] <- ilogit(vuln.s.b0 + b.censor.s * censor[s] +
b.subject[s])
vuln.s[s] ~ .(dbeta.munu(vuln.s.mu[s], nu))
vuln.s.pred[s] ~ .(dbeta.munu(vuln.s.mu[s], nu))
vuln.adult.mu[s] <- ilogit(vuln.adult.b0 + b.censor.adult * censor[s] +
b.subject[s])
vuln.adult[s] ~ .(dbeta.munu(vuln.adult.mu[s], nu))
vuln.adult.pred[s] ~ .(dbeta.munu(vuln.adult.mu[s], nu))
vuln.10yo.mu[s] <- ilogit(vuln.10yo.b0 + b.censor.10yo * censor[s] +
b.subject[s])
vuln.10yo[s] ~ .(dbeta.munu(vuln.10yo.mu[s], nu))
vuln.10yo.pred[s] ~ .(dbeta.munu(vuln.10yo.mu[s], nu))}}),
mk.inits = function() list(
vuln.s.b0 = runif(1, -2, 2),
vuln.adult.b0 = runif(1, -2, 2),
vuln.10yo.b0 = runif(1, -2, 2),
b.censor.s = runif(1, -2, 2),
b.censor.adult = runif(1, -2, 2),
b.censor.10yo = runif(1, -2, 2),
b.subject.sigma = runif(1, .1, 3),
nu = exp(runif(1, log(2), log(500)))),
jags.sample.monitor = qw(vuln.s.pred, vuln.adult.pred, vuln.10yo.pred))
tv3.model1.fake.p = list(
vuln.s.b0 = -.75,
vuln.adult.b0 = 0,
vuln.10yo.b0 = 1,
b.censor.s = -.25,
b.censor.adult = .25,
b.censor.10yo = .25,
b.subject.sigma = .25,
nu = 7)
tv3.model1.fake = function() with(tv3.model1.fake.p,
{set.seed(10)
N.subjects = 100
censor = sort(rep(c(0, 1), len = N.subjects))
b.subject = rnorm(N.subjects, 0, b.subject.sigma)
vuln.s.mu = ilogit(vuln.s.b0 + b.censor.s * censor +
b.subject)
vuln.s = rbeta.munu(N.subjects, vuln.s.mu, nu)
vuln.adult.mu = ilogit(vuln.adult.b0 + b.censor.adult * censor +
b.subject)
vuln.adult = rbeta.munu(N.subjects, vuln.adult.mu, nu)
vuln.10yo.mu = ilogit(vuln.10yo.b0 + b.censor.10yo * censor +
b.subject)
vuln.10yo = rbeta.munu(N.subjects, vuln.10yo.mu, nu)
data.frame(censor = logi2factor(censor, qw(NoOpp, Censor)),
vuln.s, vuln.adult, vuln.10yo)})
j.tv3.m1.fake = cached(vulnjags(tv3.model1, tv3.model1.fake(), n.adapt = 2500))
gelman.diag(j.tv3.m1.fake$samp)
| Upper C.I. | |
|---|---|
b.censor.10yo |
1.06 |
b.censor.adult |
1.00 |
b.censor.s |
1.01 |
b.subject.sigma |
1.19 |
nu |
1.03 |
vuln.10yo.b0 |
1.06 |
vuln.adult.b0 |
1.00 |
vuln.s.b0 |
1.03 |
The value of b.subject.sigma is a tad high (I aim for 1.1 and below), but I didn't have this problem while fitting the real data below, so no big deal.
coda.qmean(j.tv3.m1.fake$samp, tv3.model1.fake.p)
| b.censor.10yo | b.censor.adult | b.censor.s | b.subject.sigma | nu | vuln.10yo.b0 | vuln.adult.b0 | vuln.s.b0 | |
|---|---|---|---|---|---|---|---|---|
| hi | 0.760 | 0.4900 | -0.0263 | 0.267 | 7.74 | 1.050 | 0.2480 | -0.565 |
| mean | 0.458 | 0.2040 | -0.3000 | 0.161 | 6.64 | 0.833 | 0.0448 | -0.778 |
| true | 0.250 | 0.2500 | -0.2500 | 0.250 | 7.00 | 1.000 | 0.0000 | -0.750 |
| lo | 0.168 | -0.0848 | -0.5880 | 0.103 | 5.65 | 0.627 | -0.1480 | -0.998 |
Generally, things looks good (nu is surprisingly good), although the intervals are wider than I'd like.
j.tv3.m1.real = cached(vulnjags(tv3.model1,
ss(sb, tv %in% 3:5 & censor != "Refuse"),
n.adapt = 1000))
j.tv3.m1.real$d = vuln.jags2df(j.tv3.m1.real)
gelman.diag(j.tv3.m1.real$samp)
| Upper C.I. | |
|---|---|
b.censor.10yo |
1.03 |
b.censor.adult |
1.01 |
b.censor.s |
1.02 |
b.subject.sigma |
1.07 |
nu |
1.01 |
vuln.10yo.b0 |
1.01 |
vuln.adult.b0 |
1.02 |
vuln.s.b0 |
1.00 |
coda.qmean(j.tv3.m1.real$samp)
| b.censor.10yo | b.censor.adult | b.censor.s | b.subject.sigma | nu | vuln.10yo.b0 | vuln.adult.b0 | vuln.s.b0 | |
|---|---|---|---|---|---|---|---|---|
| lo | -0.607 | -0.956 | -0.8740 | 0.318 | 2.67 | 1.00 | 0.012 | -1.3000 |
| mean | 0.107 | -0.156 | -0.0885 | 0.632 | 3.81 | 1.49 | 0.588 | -0.6870 |
| hi | 0.856 | 0.606 | 0.7140 | 1.030 | 5.17 | 2.02 | 1.180 | -0.0965 |
We can be reasonably sure the vuln.*.b0s are each on the right side of 0. That is, subjects feel (1) that they themselves are unlikely to be affected by the movie, but (2) typical adults and typical 10-year-olds are likely to be affected. I've replicated the third-person effect. Excellent.
Also, b.subject.sigma is large and nu is small. That is, individual differences and noise in vulnerability judgments are large. So I expected.
Unfortunately, we can't say much about the b.censor.*s yet. These parameters are of most interest, since they determine the effect of the manipulation on each judgment.
sapply(qw(b.censor.s, b.censor.adult, b.censor.10yo), function(v)
mean(c(recursive = T, j.tv3.m1.real$samp[,v]) > 0))
| value | |
|---|---|
| b.censor.s | 0.435 |
| b.censor.adult | 0.385 |
| b.censor.10yo | 0.610 |
At least b.censor.s is in the right direction: I want b.censor.s to be negative because exercising censorship should make one feel less vulnerable to media effects. I'm less sure what to predict about the other two.
Posterior predictive checking
Now let's see how well the model's predictions match the data.
First: are the dispersions of the vulnerability judgments for each target, operationalized as the SDs, reasonable under the model?
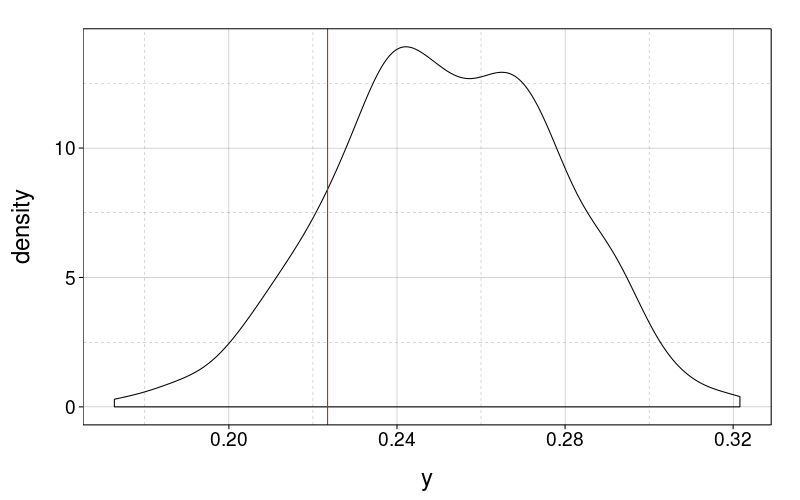
vulnjags.ppc(ss(j.tv3.m1.real$d, target == "vuln.s"), sd)

vulnjags.ppc(ss(j.tv3.m1.real$d, target == "vuln.adult"), sd)
vulnjags.ppc(ss(j.tv3.m1.real$d, target == "vuln.10yo"), sd)
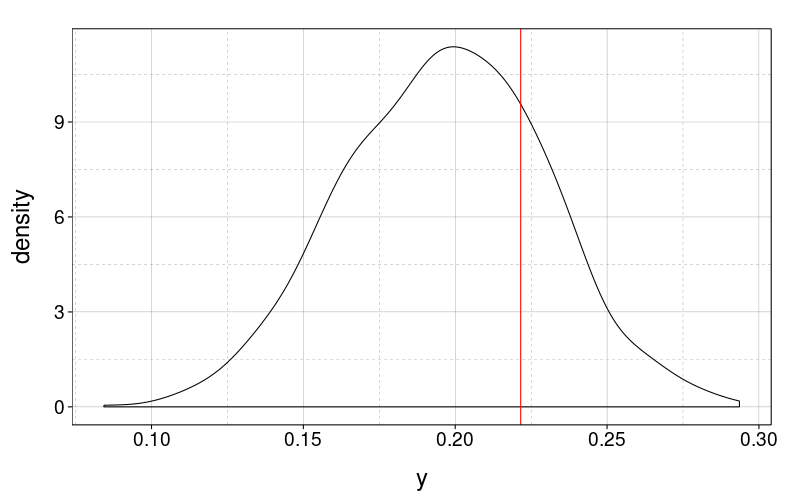
Yes, they are.
How about the dispersion within subjects across targets? Let's measure each subject's dispersion as the range, since there's only 3 judgments per subject. First, let's look at mean dispersions.
f = function(slice) mean(aggregate(y ~ subject, slice, FUN = rng)$y)
d = ddply(ss(j.tv3.m1.real$d, type == "pred"), .(i),
function(slice) data.frame(y = f(slice)))
ggplot(d) +
geom_densitybw(aes(y)) +
geom_vline(
aes_string(xintercept =
f(ss(j.tv3.m1.real$d, type == "real"))),
color = "red")
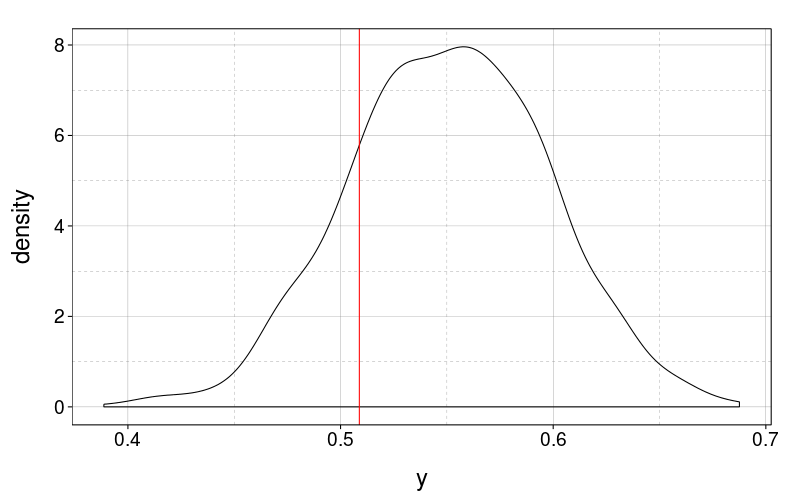
That's reasonable. How about the standard deviation of the dispersions?
f = function(slice) sd(aggregate(y ~ subject, slice, FUN = rng)$y)
d = ddply(ss(j.tv3.m1.real$d, type == "pred"), .(i),
function(slice) data.frame(y = f(slice)))
ggplot(d) +
geom_densitybw(aes(y)) +
geom_vline(
aes_string(xintercept =
f(ss(j.tv3.m1.real$d, type == "real"))),
color = "red")
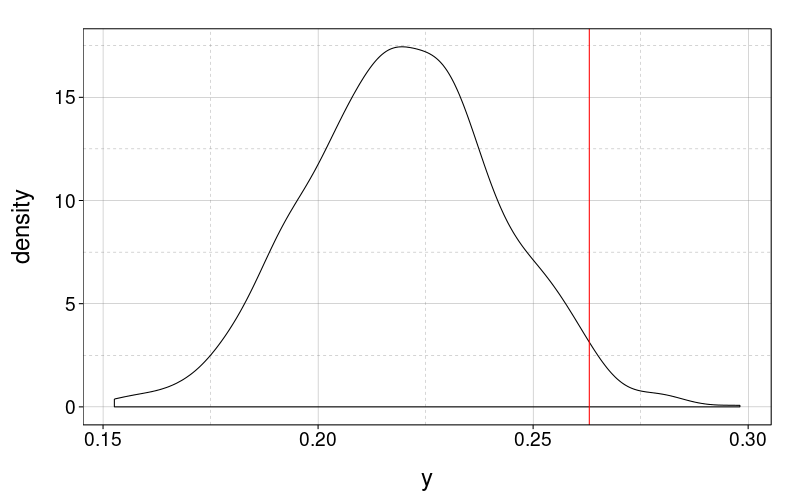
Uh-oh. The p-value is
ecdf(d$y)(f(ss(j.tv3.m1.real$d, type == "real")))
| value | |
|---|---|
| 0.98 |
which is pretty extreme. So it looks like the model is underestimating the variability in within-subject variabilities. That's a hint that my single per-subject random effect shared between the targets is too restrictive. Now, if I had a per-subject and per-target random effect instead, I would be faced with the difficult question of how to include subject indicators in the hierarchy. Or I could let the nu parameter vary per subject.
Boy, building and validating fully Bayesian models for even slightly complex datasets is a lot of work, huh? Indeed, such a job can be a full research project in an of itself. Perhaps I should stick to simpler methods for everyday data analysis, and attempt a full Bayesian approach only when modeling (that is, prediction) is my central concern.
The media-psychology angle
The previous study (TVs 3 to 5) can be summarized thus: the censorship opportunity had no sizable effect on vulnerability perceptions of oneself or of others, and it had no sizable effect on the third-person effect (i.e., the differences between these vulnerability perceptions). This finding is a blow to my hypothesis of vicarious restraint. But rather than focusing on trying to test that hypothesis further, let's take the media-psychology angle I spoke of before. If I can show convincingly that exercising censorship doesn't affect the third-person effect, the conventional idea that the third-person effect causes censorship, rather than the reverse, is strengthened. I can argue that the idea of censorship causing a third-person effect is credible enough to be worth falsifying by invoking the idea of vicarious restraint. So I'm imagining a paper with three studies:
- The one I just conducted.
- A stronger demonstration that censorship can't cause the third-person effect.
- A demonstration that the third-person effect can cause censorship.
Yeah, study 3 could be really hard. Whatever; one step at a time. My question for now is the design of study 2.
Let's make the manipulation within-subjects. I'll give each subject two scenarios to make vulnerability judgments about, presented in a random order. For one of the two scenarios, chosen randomly, the subject will have a censorship opportunity. Judgments for the different scenarios can be compared by normalizing across all subjects' judgments for each scenario.
To make the task more realistically represent real-world instances of censorship, let's make the scenarios hypothetical and have the subject imagine they're on an entertainment review board or a government panel or something. The censorship activity can be restricting access to the message (for example, adding an age restriction) rather than actually changing it.
References
Cohen, J., Mutz, D., Price, V., & Gunther, A. (1988). Perceived impact on defamation: An experiment on third-person effects. Public Opinion Quarterly, 52(2), 161–173. doi:10.1086/269092
Elder, T. J., Douglas, K. M., & Sutton, R. M. (2006). Perceptions of social influence when messages favour "us" versus "them": A closer look at the social distance effect. European Journal of Social Psychology, 36(3), 353–365. doi:10.1002/ejsp.300
Feng, G. C., & Guo, S. Z. (2012). Support for censorship: A multilevel meta-analysis of the third-person effect. Communication Reports, 25(1), 40–50. doi:10.1080/08934215.2012.661019
Jordan, J., Mullen, E., & Murnighan, J. K. (2011). Striving for the moral self: The effects of recalling past moral actions on future moral behavior. Personality and Social Psychology Bulletin, 37(5), 701–713. doi:10.1177/0146167211400208
Kouchaki, M. (2011). Vicarious moral licensing: The influence of others' past moral actions on moral behavior. Journal of Personality and Social Psychology, 101(4), 702–715. doi:10.1037/a0024552
Mazar, N., & Zhong, C. B. (2010). Do green products make us better people? Psychological Science, 21(4), 494–498. doi:10.1177/0956797610363538
Merritt, A. C., Effron, D. A., & Monin, B. (2010). Moral self-licensing: When being good frees us to be bad. Social and Personality Psychology Compass, 4(5), 344–357. doi:10.1111/j.1751-9004.2010.00263.x. Retrieved from http://wat1224.ucr.edu/Morality/Monin%202010%20Compass%20on%20Moral%20Licensing.pdf
Monin, B., & Miller, D. T. (2001). Moral credentials and the expression of prejudice. Journal of Personality and Social Psychology, 81(1), 33–43. doi:10.1037/0022-3514.81.1.33
Sachdeva, S., Iliev, R., & Medin, D. L. (2009). Sinning saints and saintly sinners: The paradox of moral self-regulation. Psychological Science, 20(4), 523–528. doi:10.1111/j.1467-9280.2009.02326.x